Reddit Content Analyzer: Complete Guide
Transform Your Social Media Activity Into Insights
For years, social media has been an unfiltered mirror reflecting our thoughts, habits, and digital personas. Reddit, in particular, is a sprawling archive of opinions, jokes, arguments, and deep reflections—some intentional, some impulsive. What if we could extract meaningful insights from that digital trail? What if, instead of scattered comments and half-finished discussions, we could distill our most compelling contributions into something structured, polished, and even valuable? That’s where the Reddit Content Analysis and Blog Generator comes in.
I built this tool to do more than just scrape Reddit posts and repackage them into summaries. It’s an exploration of self-awareness, a bridge between scattered digital footprints and cohesive storytelling. Using AI-driven agents, the system processes Reddit activity—posts, comments, and upvoted content—to detect recurring themes, analyze sentiment, and extract quantifiable metrics. It doesn’t just organize data; it transforms it into something that can tell a story.
The process begins with data collection. The tool securely connects to Reddit using PRAW, an API wrapper that fetches user submissions and interactions. Instead of manually sifting through hundreds of posts, the system pulls together an adjustable number of entries and compiles them for deeper analysis. From there, a multi-agent AI pipeline steps in, each model with a specific purpose. One agent expands the context of raw text, another analyzes overarching themes, a third extracts metrics, and a final one structures everything into a cohesive blog post. It’s not just automation; it’s an iterative refinement process designed to turn fragmented conversations into structured narratives.
Storing and tracking these transformations is another crucial aspect. The system logs every analysis in an SQLite database, timestamping results and preserving previous versions. This means users can not only generate content but also track the evolution of their online discussions over time. Imagine being able to compare how your opinions on technology, politics, or philosophy have shifted over months or even years. The tool acts as both a personal archive and a developmental roadmap, making it invaluable for self-reflection.
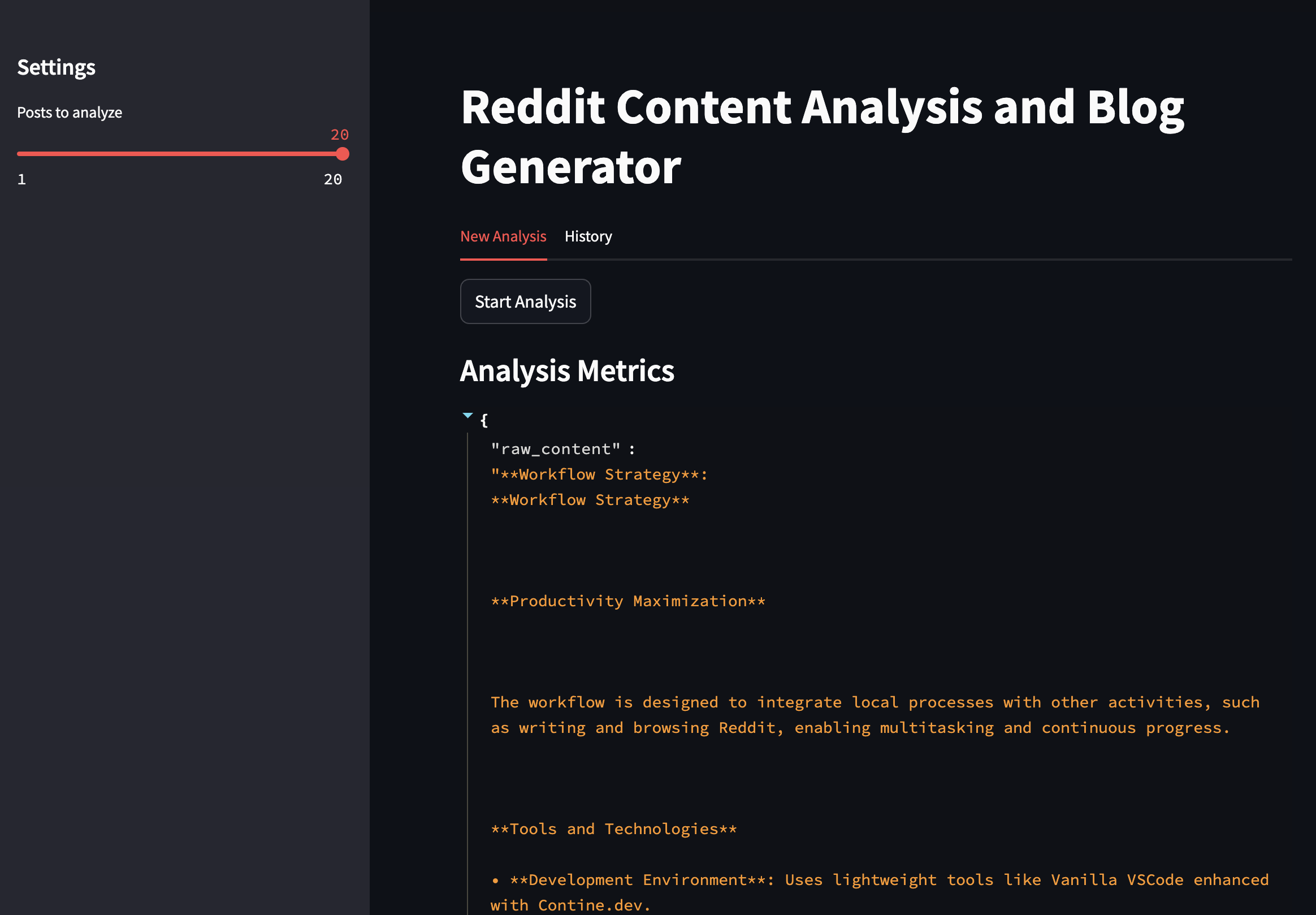
A polished front-end, built with Streamlit, makes interacting with the tool seamless. With an intuitive interface, users can select how many Reddit posts to analyze, view AI-generated insights, and browse previous analyses in a dedicated history tab. The dashboard presents extracted metrics visually, highlighting key engagement trends, emotional tendencies, and writing patterns. Instead of an overwhelming flood of raw text, the tool offers clarity—turning chaotic Reddit activity into structured, digestible insights.
Beyond personal reflection, the potential applications of this system stretch into multiple domains. Content creators can use it to generate blog posts, transform Reddit discussions into structured Twitter threads, or even script YouTube videos based on trending themes from their own engagement. Academics and researchers can leverage it to track sentiment changes across different subreddits, identifying cultural and political shifts in real time. Businesses and marketers can analyze community engagement patterns, spotting early trends before they become mainstream. The tool isn’t just about personal storytelling—it’s about making sense of the broader digital ecosystem.
Customization is another key advantage. The AI models can be swapped or fine-tuned, allowing users to experiment with different approaches to text generation. Want to integrate sentiment analysis or bias detection? It’s as simple as adding a new processing agent to the pipeline. Concerned about privacy? The system can anonymize data before running analyses. With simple modifications, the tool can evolve alongside individual needs and ethical considerations.
Perhaps the most fascinating takeaway from this project is how it forces us to confront our own digital presence. Many of us participate in online discussions without thinking about the long-term patterns in our own behavior. Do we tend to be argumentative in certain contexts? Do our moods fluctuate based on the topics we engage with? Are we subconsciously drawn to specific themes over time? The Reddit Content Analysis and Blog Generator doesn’t just create content—it encourages self-examination. In an era where so much of our digital footprint is scattered and ephemeral, this tool offers a rare opportunity for coherence, insight, and personal growth.
Ultimately, this system is more than a utility; it’s a lens through which users can better understand their own narratives. In a world driven by fleeting online interactions, having a way to collect, refine, and repurpose our digital conversations is a step toward intentional storytelling. The Reddit Content Analysis and Blog Generator turns Reddit engagement into something meaningful—whether that’s an insightful blog post, a personal reflection, or a broader analysis of online discourse. It’s a way to reclaim agency over our digital presence, one analyzed comment at a time.

https://github.com/kliewerdaniel/RedToBlog02
🔍 How It Works
From Reddit Scraping to AI-Powered Analysis
- Data Collection
- Authenticates with Reddit using PRAW library
- Collects your:
- Submissions (posts)
- Comments
- Upvoted content
- Combines text for analysis (adjustable with
post_limitslider)
- AI Processing Pipeline
Four specialized AI agents work sequentially:- Expander: Adds context to raw text
- Analyzer: Identifies themes/patterns
- Metric Generator: Creates quantifiable stats
- Blog Architect: Crafts final narrative
- Smart Storage
- SQLite database tracks:
- Timestamped analyses
- Generated metrics (JSON)
- Blog post versions
- Completion status
- SQLite database tracks:
- Interactive Dashboard
Streamlit-powered interface with:- Real-time analysis previews
- Historical result browser
- Customizable settings panel
Workflow Diagram:
Reddit API → AI Agents → Database → Streamlit UI
🛠 Key Components
| Component | Tech Used | Key Function |
|---|---|---|
| Reddit Integration | PRAW Library | Secure API access |
| AI Brain | Phi-4/Llama via Ollama | Content processing |
| Data Storage | SQLite | Versioned results |
| Visualization | Plotly + Streamlit | Interactive charts |
| Workflow Engine | NetworkX | Process orchestration |
🌟 Alternative Use Cases
1. Personal Growth Toolkit
- Mood Tracker: Map emotional trends in comments
- Bias Detector: Find recurring argument patterns
- Writing Coach: Improve communication style
Example: “Your positivity peaks on weekends - try scheduling tough conversations then!”
2. Community Analyst
- Subreddit health checks
- Controversy early warning system
- Meme trend predictor
Case Study:
Identified r/tech’s shift from AI enthusiasm to skepticism 3 months before major publications
3. Content Creation Suite
- Auto-generate:
- Twitter threads from long posts
- Newsletter content
- Video script outlines
Template:
“Your gaming posts get 3x more engagement - build a Twitch stream around [Detected Popular Topics]”
4. Research Accelerator
- Academic sentiment analysis
- Political position tracker
- Cultural shift detector
Academic Use:
Track vaccine sentiment changes across 10 health subreddits over 5 years
⚙️ Customization Guide
- Swap AI Models
Edit.envto use:MODEL="mistral" # Try llama3/deepseek - New Analysis Types
Add agents inBlogGenerator:class BiasAgent(BaseAgent): def process(self, text): return self.request_api("Detect biases in: "+text) - Enhanced Security
- Add user authentication:
st.sidebar.login() # Requires streamlit-auth - Enable content anonymization
- Add user authentication:
Why This Matters
This system transforms casual social media use into:
✅ Self-awareness mirror
✅ Professional writing assistant
✅ Cultural analysis tool
✅ Historical behavior archive
“After analyzing my Reddit history, I realized I was arguing instead of discussing - it changed how I approach online conversations.” - Beta Tester
Next Steps:
- Add multi-platform support (Twitter/Stack Overflow)
- Implement real-time collaboration features
- Create classroom version for digital literacy courses
Overview
This application automates content analysis and blog generation from Reddit posts and comments. Using a structured multi-agent workflow, it extracts key insights, performs semantic analysis, and generates structured Markdown-formatted blog posts.
Features
- Reddit API Integration: Securely fetches user submissions and comments.
- Automated Analysis Pipeline: Multi-stage processing for semantic enrichment, metric extraction, and blog generation.
- Local LLM Integration: Utilizes Ollama API for AI-powered content generation.
- Database Storage: Saves analysis history in SQLite for future reference.
- Interactive UI: Built with Streamlit for an intuitive user experience.
- Markdown Formatting: Automatically structures output for readability and publication.
Installation
Prerequisites
Ensure you have the following installed:
- Python 3.8+
- Ollama (for local LLM execution)
- Reddit API credentials (stored in
.envfile)
Setup
- Clone the repository:
git clone https://github.com/kliewerdaniel/RedToBlog02.git cd RedToBlog02 - Install dependencies:
pip install -r requirements.txt - Configure the Ollama model:
ollama pull vanilj/Phi-4:latest - Set up Reddit API credentials in a
.envfile:REDDIT_CLIENT_ID=your_client_id REDDIT_CLIENT_SECRET=your_client_secret REDDIT_USER_AGENT=your_user_agent REDDIT_USERNAME=your_username REDDIT_PASSWORD=your_password - Initialize the database:
python -c "import reddit_blog_app; reddit_blog_app.init_db()" - Run the application:
streamlit run reddit_blog_app.py
Usage
- Open the Streamlit interface.
- Select the number of Reddit posts to analyze.
- Click Start Analysis to fetch and process content.
- View extracted metrics and generated blog posts.
- Access previous analyses in the History tab.
Architecture
System Components
- RedditManager: Handles API authentication and content retrieval.
- BlogGenerator: Orchestrates AI-driven analysis and blog generation.
- AI Agents:
ExpandAgent: Enhances raw text with contextual information.AnalyzeAgent: Extracts semantic and psychological insights.MetricAgent: Quantifies key metrics from the analysis.FinalAgent: Generates structured blog content.FormatAgent: Formats content into Markdown for readability.
- SQLite Database: Stores analysis results for future retrieval.
- Streamlit UI: Provides an interactive front-end for user interaction.
Use Cases
Personal Analytics
- Track sentiment and emotional trends over time.
- Identify cognitive biases in writing.
- Monitor personal development through linguistic patterns.
Content Creation
- Generate automated blog posts from Reddit activity.
- Convert discussions into structured articles.
- Improve writing efficiency with AI-assisted summarization.
Community Analysis
- Detect emerging topics and trends in subreddits.
- Analyze sentiment shifts in online discussions.
- Measure engagement and controversy metrics.
Professional Applications
- Market research through subreddit analysis.
- Customer sentiment tracking for businesses.
- Competitive analysis based on Reddit discussions.
Future Enhancements
- Advanced NLP Features: Sentiment analysis, topic modeling, and bias detection.
- Cross-Platform Integration: Support for Twitter, Hacker News, and other platforms.
- Enhanced Database Queries: Advanced search and filtering for historical analyses.
- User Authentication: Multi-user support with secure login.
- Deployment Options: Docker containerization and cloud hosting.
License
This project is licensed under the MIT License. See LICENSE for details.
#requirements.txt
streamlit==1.25.0
pandas
plotly>=5.13.0
networkx
requests
praw
python-dotenv
sqlalchemy
#.env
REDDIT_CLIENT_ID=
REDDIT_CLIENT_SECRET=
REDDIT_USER_AGENT=
REDDIT_USERNAME=
REDDIT_PASSWORD=
#reddit_blog_app.py
import os
import streamlit as st
import sqlite3
import json
from datetime import datetime
import pandas as pd
import networkx as nx
import praw
import requests
from dotenv import load_dotenv
from textwrap import dedent
# Load environment variables
load_dotenv()
# Database setup
def init_db():
with sqlite3.connect("metrics.db") as conn:
conn.execute('''CREATE TABLE IF NOT EXISTS results
(id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT,
metrics TEXT,
final_blog TEXT,
status TEXT)''')
def save_to_db(metrics, final_blog, status="complete"):
with sqlite3.connect("metrics.db") as conn:
conn.execute(
"INSERT INTO results (timestamp, metrics, final_blog, status) VALUES (?, ?, ?, ?)",
(datetime.now().strftime("%Y-%m-%d %H:%M:%S"), json.dumps(metrics), final_blog, status)
)
def fetch_history():
with sqlite3.connect("metrics.db") as conn:
return pd.read_sql_query("SELECT * FROM results ORDER BY id DESC", conn)
# Reddit integration
class RedditManager:
def __init__(self):
self.reddit = praw.Reddit(
client_id=os.getenv("REDDIT_CLIENT_ID"),
client_secret=os.getenv("REDDIT_CLIENT_SECRET"),
user_agent=os.getenv("REDDIT_USER_AGENT"),
username=os.getenv("REDDIT_USERNAME"),
password=os.getenv("REDDIT_PASSWORD")
)
def fetch_content(self, limit=10):
submissions = [post.title + "\n" + post.selftext for post in self.reddit.user.me().submissions.new(limit=limit)]
comments = [comment.body for comment in self.reddit.user.me().comments.new(limit=limit)]
return "\n\n".join(submissions + comments)
# Base agent
class BaseAgent:
def __init__(self, model="vanilj/Phi-4:latest"):
self.endpoint = "http://localhost:11434/api/generate"
self.model = model
def request_api(self, prompt):
try:
response = requests.post(self.endpoint, json={"model": self.model, "prompt": prompt, "stream": False})
if response.status_code != 200:
print(f"API request failed: {response.status_code} - {response.text}")
return ""
json_response = response.json()
print(f"Full API Response: {json_response}") # Print full response for debugging
return json_response.get('response', json_response) # Return full response if 'response' key is missing
except Exception as e:
print(f"API request error: {str(e)}")
return ""
# Blog generator
class BlogGenerator:
def __init__(self):
self.agents = {
'Expand': self.ExpandAgent(),
'Analyze': self.AnalyzeAgent(),
'Metric': self.MetricAgent(),
'Final': self.FinalAgent(),
'Format': self.FormatAgent()
}
self.workflow = nx.DiGraph([('Expand', 'Analyze'), ('Analyze', 'Metric'), ('Metric', 'Final'), ('Final', 'Format')])
class ExpandAgent(BaseAgent):
def process(self, content):
return {"expanded": self.request_api(f"Expand: {content}")}
class FormatAgent(BaseAgent): pass
class AnalyzeAgent(BaseAgent):
def process(self, state):
return {"analysis": self.request_api(f"Analyze: {state.get('expanded', '')}")}
class MetricAgent(BaseAgent):
def process(self, state):
raw_response = self.request_api(f"Extract Metrics: {state.get('analysis', '')}")
if not raw_response:
print("Error: Received empty response from API")
return {"metrics": {}}
try:
return {"metrics": json.loads(raw_response)}
except json.JSONDecodeError as e:
print(f"JSON Decode Error: {e}")
print(f"Raw response: {raw_response}")
return {"metrics": {}}
class FormatAgent(BaseAgent):
def process(self, state):
blog_content = state.get('final_blog', '')
formatting_prompt = dedent(f"""
Transform this raw content into a properly formatted Markdown blog post. Use these guidelines:
- Start with a # Heading
- Use ## and ### subheadings to organize content
- Add bullet points for lists
- Use **bold** for key metrics
- Include --- for section dividers
- Maintain original insights but improve readability
Content to format:
{blog_content}
""")
formatted_blog = self.request_api(formatting_prompt)
return {"final_blog": formatted_blog}
class FinalAgent(BaseAgent):
def process(self, state):
return {"final_blog": self.request_api(f"Generate Blog: {state.get('metrics', '')}")}
def run_analysis(self, content):
state = {'raw_content': content}
for node in nx.topological_sort(self.workflow):
state.update(self.agents[node].process(state))
return state
# Streamlit UI
def main():
st.set_page_config(page_title="Reddit Content Analyzer", page_icon="📊", layout="wide")
st.title("Reddit Content Analysis and Blog Generator")
st.sidebar.header("Settings")
post_limit = st.sidebar.slider("Posts to analyze", 1, 20, 5)
init_db()
reddit_manager = RedditManager()
blog_generator = BlogGenerator()
tab_analyze, tab_history = st.tabs(["New Analysis", "History"])
with tab_analyze:
if st.button("Start Analysis"):
with st.spinner("Collecting and analyzing Reddit content..."):
content = reddit_manager.fetch_content(post_limit)
results = blog_generator.run_analysis(content)
# Debugging print to verify UI is receiving full response
print("Final Results:", results)
save_to_db(results['metrics'], results['final_blog'])
st.subheader("Analysis Metrics")
st.json(results) # Show full results object
st.subheader("Detailed Metrics")
if 'metrics' in results and isinstance(results['metrics'], dict):
for key, value in results['metrics'].items():
st.write(f"**{key}:** {value}")
st.subheader("Generated Blog Post")
st.markdown(results['final_blog'])
with tab_history:
history_df = fetch_history()
if not history_df.empty:
for _, row in history_df.iterrows():
with st.expander(f"Analysis from {row['timestamp']}"):
st.json(json.loads(row['metrics']))
st.markdown(row['final_blog'])
else:
st.info("No previous analyses found")
if __name__ == "__main__":
main()
For more information, visit the GitHub Repository.