Behind the Scenes of RedDiss: Crafting AI-Powered Diss Tracks from Reddit
In the ever-evolving landscape of artificial intelligence and social media, innovative projects continually push the boundaries of what’s possible. One such pioneering endeavor is RedDiss, an AI-powered diss track generator developed by Daniel Kliewer. As an entry for the Loco Local LocalLLaMa Hackathon 1.0, RedDiss seamlessly blends Reddit data extraction with cutting-edge AI technologies to produce personalized diss tracks. This blog post delves deep into the architecture, functionalities, and inner workings of RedDiss, offering a comprehensive overview of how this project transforms raw Reddit content into polished auditory art.
Table of Contents
- Introduction to RedDiss
- Project Architecture
- Core Components
- Streamlit Front-End
- Backend Integration with FastAPI
- Testing and Quality Assurance
- Installation and Deployment
- Conclusion and Future Prospects
Introduction to RedDiss
RedDiss stands at the intersection of social media analytics, natural language processing, and audio engineering. By harnessing the wealth of conversations on Reddit, RedDiss extracts relevant themes and sentiments to craft diss track lyrics tailored to specific Reddit posts or comments. These lyrics are then refined for flow, converted to speech, synchronized with beats, and masterfully processed into a final audio track—all within an intuitive Streamlit application.
Project Architecture
RedDiss is structured to ensure maintainability, scalability, and efficiency. The project repository is organized into several key directories:
- agents/: Contains modules responsible for each processing step, from scraping to mastering.
- models/: Hosts AI models and related files.
- data/: Stores raw, processed, and generated data, including lyrics and audio files.
- tests/: Includes test cases to validate the functionality of various components.
- streamlit_app.py: The front-end interface built with Streamlit.
- main.py: The FastAPI backend handling API requests.
- combined_output.txt: Aggregated logs or outputs from the combine script.
- requirements.txt: Lists all dependencies required to run RedDiss.
- .env: Stores environment variables, such as Reddit API credentials.
This modular architecture allows each component to operate independently while seamlessly integrating with others, fostering an environment conducive to continuous development and improvement.
Core Components
Let’s explore each core component of RedDiss, understanding its purpose and implementation.
1. Reddit Data Scraper
File: agents/scraper.py
RedDiss begins its magic by tapping into Reddit’s vast repository of posts and comments. Utilizing the asyncpraw library, an asynchronous Reddit API wrapper, the scraper fetches content based on user-provided URLs. Here’s a glimpse into its functionality:
class RedditScraper:
def __init__(self):
# Initialize Reddit client with credentials
self.reddit = asyncpraw.Reddit(
client_id=os.getenv("REDDIT_CLIENT_ID"),
client_secret=os.getenv("REDDIT_CLIENT_SECRET"),
user_agent=os.getenv("REDDIT_USER_AGENT")
)
async def extract_post_data(self, url: str) -> Dict[str, Any]:
# Fetch and process submission data
submission = await self.reddit.submission(url=url)
await submission.load()
# Extract relevant details and comments
# ...
The scraper ensures that only meaningful and non-deprecated directories (like venv/) are accessed, maintaining the integrity and security of the data extraction process.
2. Text Sanitization
File: agents/sanitizer.py
Raw Reddit data often contains noise—URLs, markdown formatting, special characters, and more. The sanitizer cleans and normalizes this content, making it suitable for further processing.
async def clean_text(content: Dict[str, Any]) -> Dict[str, Any]:
# Clean title and main text
cleaned_data = {
"title": _clean_string(content["title"]),
"main_text": _clean_string(content["selftext"]),
# ...
}
# Filter and clean comments
# ...
return cleaned_data
This step is crucial for ensuring that subsequent analyses, like theme extraction and lyrics generation, operate on clear and concise text.
3. Theme Extraction
File: agents/theme_extractor.py
Understanding the themes and sentiments within the Reddit content is pivotal for generating relevant diss tracks. Leveraging Hugging Face’s transformers library, RedDiss employs a zero-shot classification pipeline to identify dominant themes.
class ThemeExtractor:
def __init__(self):
self.classifier = pipeline(
"zero-shot-classification",
model="facebook/bart-large-mnli",
device=-1 # CPU usage
)
self.candidate_themes = ["wealth/money", "success/achievements", ...]
async def extract_themes(self, content: Dict[str, Any]) -> Dict[str, Any]:
main_themes = await self._classify_text(main_content)
# Extract themes from comments
# ...
return themes_data
By analyzing both the main content and top comments, the theme extractor ensures a comprehensive understanding of the target’s discourse.
4. Lyrics Generation
File: agents/lyrics_generator.py
At the heart of RedDiss lies its ability to craft diss track lyrics. Utilizing Llama 3.3 through the litellm library, the generator produces verses tailored to the extracted themes and chosen style.
class LyricsGenerator:
def __init__(self):
self.model = "ollama/llama3.3:latest"
async def generate_lyrics(self, themes: Dict[str, Any], style: str) -> Dict[str, Any]:
context = self._build_context(themes, style)
lyrics = await self._generate_verses(context)
structured_lyrics = self._structure_lyrics(lyrics)
return structured_lyrics
The lyrics are scaffolded into structured formats, including verses, chorus, and outro, ensuring a coherent and impactful flow.
5. Flow Refinement
File: agents/flow_refiner.py
Raw lyrics can benefit from refinement to enhance their rhythmic and rhyming quality. The flow refiner employs Llama 3.3 to polish the generated lyrics, focusing on internal rhyme schemes, wordplay, and punchline effectiveness.
class FlowRefiner:
def __init__(self):
self.model = "ollama/llama3.3:latest"
async def refine_flow(self, lyrics: Dict[str, Any], flow_complexity: int) -> Dict[str, Any]:
refined_lyrics = {}
for section, content in lyrics.items():
refined_lyrics[section] = await self._enhance_section(content, section, flow_complexity)
return refined_lyrics
This iterative process ensures that the diss tracks resonate with the desired intensity and sophistication.
6. Text-to-Speech (TTS) Engine
File: agents/tts_engine.py
Transforming written lyrics into spoken word is achieved through the TTS engine. On macOS, RedDiss leverages the native say command, combined with ffmpeg for audio processing, to generate high-quality vocal tracks.
class TTSEngine:
def __init__(self):
# Verify availability of 'say' and 'ffmpeg'
subprocess.run(['say', '-?'], capture_output=True)
subprocess.run(['ffmpeg', '-version'], capture_output=True)
async def text_to_speech(self, lyrics: Dict[str, Any]) -> str:
audio_sections = []
for section, content in lyrics.items():
# Generate audio for each section
subprocess.run(['say', '-v', 'Daniel', '-r', '220', '-f', temp_txt.name, '-o', temp_aiff.name], check=True)
# Process with ffmpeg
subprocess.run(['ffmpeg', '-i', temp_aiff.name, '-af', 'acompressor=...', '-ar', '44100', '-ac', '1', '-y', temp_wav.name], check=True)
# Normalize and append
audio_sections.append(audio_array)
# Combine sections and save
final_audio = np.concatenate(audio_sections)
sf.write("data/audio/raw_vocals.wav", final_audio, 44100)
return "data/audio/raw_vocals.wav"
This component ensures that the diss tracks not only look good on paper but also sound compelling to the ear.
7. Beat Synchronization
File: agents/beat_sync.py
No diss track is complete without the right beat. The beat synchronizer aligns the vocal tracks with the chosen beats, ensuring timed precision and harmonious integration.
class BeatSynchronizer:
def __init__(self):
self.target_tempo = 90 # BPM
async def sync_to_beat(self, vocals_path: str, beat_url: str) -> str:
# Load vocals and beat
vocals, sr_vocals = librosa.load(vocals_path)
beat_path = await self._download_beat(beat_url)
beat, sr_beat = librosa.load(beat_path)
# Analyze tempo and synchronize
# Mix and save the final track
return "data/audio/synced_track.wav"
By adjusting tempos and aligning beats, this module ensures that the diss tracks maintain a steady and immersive rhythm.
8. Audio Mastering
File: agents/mastering.py
The final polish comes from the audio mastering component, which enhances the track’s quality, balances audio levels, and ensures consistency across platforms.
class AudioMaster:
def __init__(self):
self.target_lufs = -14.0
self.target_peak = -1.0
async def master_audio(self, audio_path: str) -> str:
# Load audio, apply compression, EQ, stereo enhancement, and limiting
# Save the mastered audio
sf.write("data/audio/mastered/final_track.wav", processed, sr)
return "data/audio/mastered/final_track.wav"
This meticulous process guarantees that each diss track is studio-quality, ready for listeners to engage and enjoy.
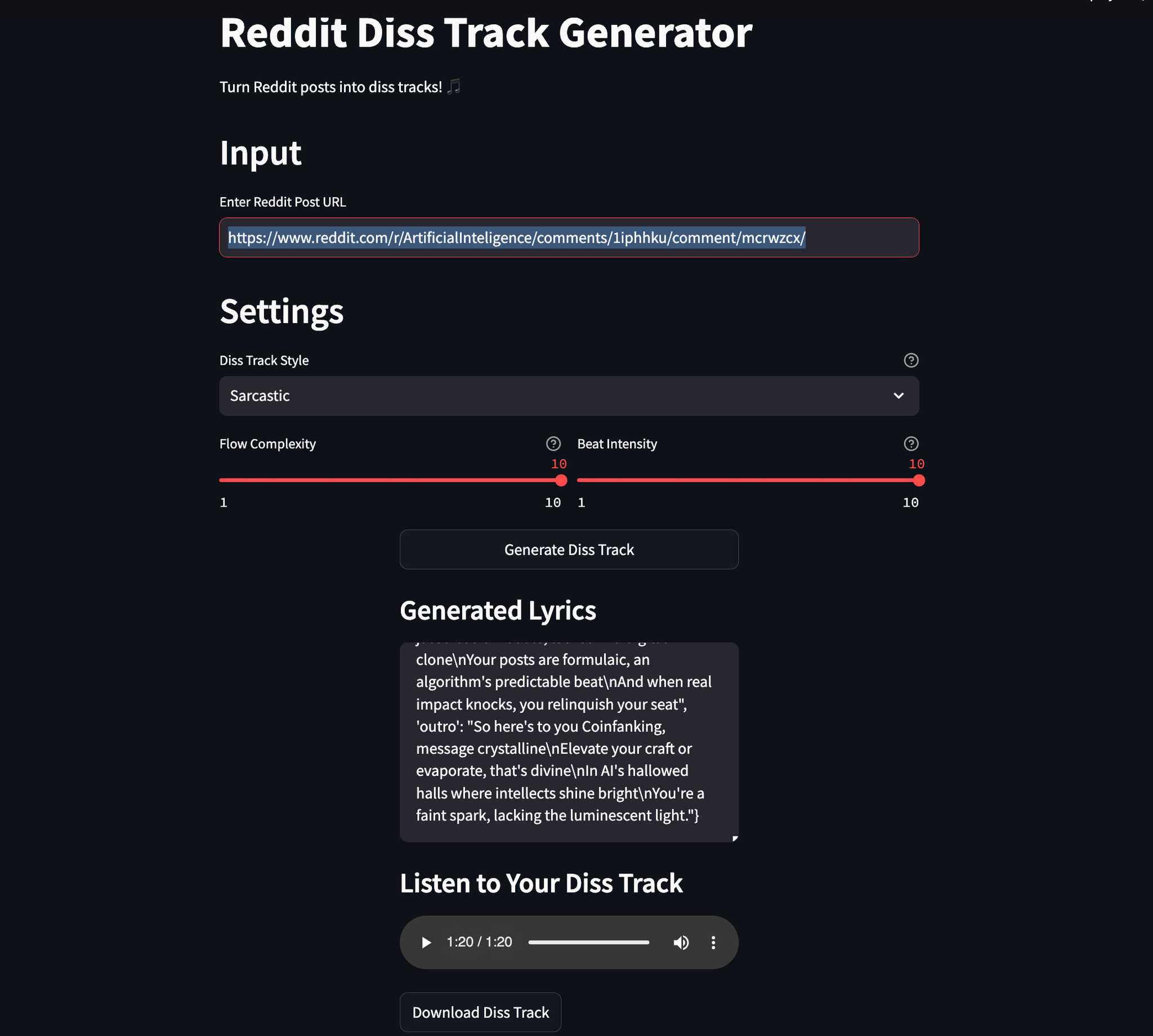
Streamlit Front-End
File: streamlit_app.py
The user-facing interface of RedDiss is built with Streamlit, offering an intuitive platform for users to generate diss tracks effortlessly.
- Input Section: Users provide a Reddit post URL.
- Settings: Options to select diss track style (Aggressive, Playful, Sarcastic), adjust flow complexity, and beat intensity.
- Generate Button: Initiates the diss track creation process.
- Output: Displays generated lyrics and an audio player for the final track, along with a download option.
def main():
st.title("Reddit Diss Track Generator")
reddit_url = st.text_input("Enter Reddit Post URL", placeholder="https://reddit.com/r/...")
style = st.selectbox("Diss Track Style", ["Aggressive", "Playful", "Sarcastic"])
flow_complexity = st.slider("Flow Complexity", 1, 10, 5)
beat_intensity = st.slider("Beat Intensity", 1, 10, 5)
if st.button("Generate Diss Track"):
# Orchestrate the diss track generation process
# Display lyrics and audio
This seamless user experience ensures that both novices and experts can harness the power of RedDiss with ease.
Backend Integration with FastAPI
File: main.py
RedDiss’s backend is powered by FastAPI, facilitating efficient handling of API requests and orchestrating the diss track generation workflow.
app = FastAPI(title="Diss Track AI", description="AI-powered diss track generator using Reddit content", version="1.0.0")
@app.get("/generate_diss")
async def generate_diss(url: str, style: str, beat_url: Optional[str] = None, flow_complexity: int = 5):
try:
# Sequentially execute scraping, sanitization, theme extraction, lyrics generation, flow refinement, TTS, beat sync, and mastering
return {"status": "success", "lyrics": refined_lyrics, "audio_file": final_track}
except Exception as e:
# Handle and log errors
raise HTTPException(status_code=500, detail={"error": str(e), "step": "unknown"})
This robust backend ensures that RedDiss can handle multiple simultaneous requests, maintaining performance and reliability.
Testing and Quality Assurance
File: tests/test_sanitizer.py
To maintain high-quality outputs, RedDiss incorporates a suite of tests using pytest. For instance, the sanitizer module is rigorously tested to ensure it effectively cleans and preprocesses Reddit content.
@pytest.mark.asyncio
async def test_clean_text():
test_data = {
"title": "Test [Post] with http://example.com URLs",
"selftext": "Some & special characters < here >",
# ...
}
result = await clean_text(test_data)
assert result["title"] == "test post with urls"
# Additional assertions
These tests validate the functionality of each component, ensuring that RedDiss operates smoothly and produces accurate results.
Installation and Deployment
File: README.md
Setting up RedDiss is straightforward, guided by comprehensive documentation. Here’s a condensed version of the installation steps:
- Clone the Repository
git clone https://github.com/kliewerdaniel/RedDiss.git cd RedDiss - Install Dependencies
pip install -r requirements.txt - Set Up Environment Variables
Create a
.envfile in the root directory with Reddit API credentials:REDDIT_CLIENT_ID=your_client_id REDDIT_CLIENT_SECRET=your_client_secret REDDIT_USER_AGENT=DissTrackAI/1.0.0 - Run the Streamlit App
streamlit run streamlit_app.py
This streamlined setup ensures that users can quickly get started, tapping into the full potential of RedDiss without unnecessary hurdles.
Conclusion and Future Prospects
RedDiss exemplifies the harmonious integration of data extraction, natural language processing, and audio engineering. By transforming raw Reddit content into personalized diss tracks, it not only showcases the capabilities of modern AI but also underscores the potential for creative applications in digital entertainment.
Daniel Kliewer’s methodical approach—evident in the project’s structured architecture and comprehensive testing—lays a solid foundation for future enhancements. Potential avenues for expansion include incorporating more diverse AI models for lyric generation, enhancing beat synchronization with a broader library of beats, and expanding the application’s reach to other social media platforms.
As AI continues to redefine the boundaries of creativity, projects like RedDiss pave the way for innovative applications that blend technology with artistic expression, offering users unique and personalized experiences in the digital age.