Instagram Feed Summarizer
Creating a Multi-Model AI Agent that monitors a user’s Instagram posts, generates detailed descriptions from images, summarizes the user’s persona, and finally crafts a comprehensive blog post based on their activity is an ambitious and rewarding project. This guide will walk you through the entire process, breaking it down into manageable steps with code examples to help you implement each component effectively.
Table of Contents
- Project Overview
- Tools and Technologies
- Setting Up the Development Environment
- Obtaining Instagram API Credentials
- Fetching Instagram Posts
- Converting Images to Text Descriptions
- Summarizing User Persona
- Generating the Blog Post
- Orchestrating the Workflow
- Handling Storage and Data Management
- Scheduling and Automation
- Error Handling and Logging
- Deployment Considerations
- Ethical and Privacy Considerations
- Conclusion
Project Overview
The goal is to develop an AI-driven pipeline that performs the following tasks:
- Monitor Instagram Posts: Continuously fetch a user’s recent Instagram posts (images and captions).
- Image-to-Text Conversion: Use a multimodal model to convert each image into a detailed text description.
- Persona Summarization: Aggregate these descriptions to create a summary profile of the user.
- Blog Post Generation: Utilize a Large Language Model (LLM) to generate a blog post based on the summarized persona and recent activity.
This pipeline leverages multiple AI models and integrates them into a seamless workflow to automate content generation.
Tools and Technologies
To build this multi-model AI agent, you’ll need to utilize several tools and libraries:
- Programming Language: Python 3.8+
- APIs:
- Instagram Graph API: To fetch user posts.
- OpenAI API: For image-to-text conversion (e.g., using GPT-4 with multimodal capabilities) and text summarization.
- Libraries:
requestsorinstagram_graph_apiwrappers for API interactions.PilloworOpenCVfor image processing (if needed).dotenvfor environment variable management.loggingfor logging activities and errors.
- Storage:
- Local storage (e.g., JSON or SQLite) or cloud storage solutions (e.g., AWS S3) to store fetched data and generated content.
- Scheduling:
scheduleorAPSchedulerfor automating the agent’s execution.
Setting Up the Development Environment
-
Install Python: Ensure you have Python 3.8 or later installed. You can download it from Python’s official website.
- Create a Project Directory:
mkdir InstagramPersonaBlogGenerator cd InstagramPersonaBlogGenerator - Initialize a Virtual Environment:
python3 -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate - Install Required Packages:
pip install requests python-dotenv Pillow openai schedule - Create Essential Files and Directories:
mkdir utils agents workflows touch main.py touch .env - Initialize Git (Optional):
git init echo "venv/" >> .gitignore echo ".env" >> .gitignore
Obtaining Instagram API Credentials
To interact with Instagram programmatically, you’ll need to use the Instagram Graph API, which is part of Facebook’s suite of developer tools.
Steps to Obtain Credentials:
- Create a Facebook Developer Account:
- Navigate to Facebook for Developers and sign up or log in.
- Create a New App:
- In the dashboard, click on “Create App”.
- Select “Business” as the app type and click “Next”.
- Enter an App Name, Contact Email, and choose a Business Account if prompted.
- Click “Create App”.
- Add Instagram Basic Display and Instagram Graph API:
- In your app dashboard, click “Add Product”.
- Select “Instagram” and set up both the Instagram Basic Display and Instagram Graph API products.
- Configure Instagram Graph API:
- Set Up Instagram Business Account:
- Convert your Instagram account to a Business or Creator account if it’s not already.
- Link your Instagram account to a Facebook Page.
- Generate Access Tokens:
- Follow the Instagram Graph API Getting Started Guide to obtain Access Tokens.
- Note: Access Tokens have expiration dates. For production use, implement token refreshing mechanisms.
- Set Up Instagram Business Account:
- Set Up Permissions:
- Request the necessary permissions such as
instagram_basic,pages_show_list,ads_management, etc., depending on your application’s needs. - App Review: If your app is intended for public use, submit it for review to obtain necessary permissions.
- Request the necessary permissions such as
- Update
.envFile:INSTAGRAM_ACCESS_TOKEN=your_instagram_access_token INSTAGRAM_USER_ID=your_instagram_user_id OPENAI_API_KEY=your_openai_api_key- Security Reminder: Ensure
.envis added to.gitignoreto prevent sensitive information from being exposed.
- Security Reminder: Ensure
Fetching Instagram Posts
With your Instagram API credentials in place, you can now fetch a user’s recent posts.
Instagram Graph API Endpoints:
- Get User Media:
GET /{user-id}/media - Get Media Details:
GET /{media-id}?fields=id,caption,media_type,media_url,permalink,timestamp
Implementation Steps:
-
Create a Utility Function to Fetch Posts:
# utils/instagram_fetcher.py import requests import os import logging from dotenv import load_dotenv load_dotenv() INSTAGRAM_ACCESS_TOKEN = os.getenv("INSTAGRAM_ACCESS_TOKEN") INSTAGRAM_USER_ID = os.getenv("INSTAGRAM_USER_ID") INSTAGRAM_API_URL = "https://graph.instagram.com" # Configure logging logging.basicConfig( filename='instagram_fetcher.log', level=logging.INFO, format='%(asctime)s %(levelname)s:%(message)s' ) def fetch_recent_posts(limit=10): endpoint = f"{INSTAGRAM_API_URL}/{INSTAGRAM_USER_ID}/media" params = { 'fields': 'id,caption,media_type,media_url,permalink,timestamp', 'access_token': INSTAGRAM_ACCESS_TOKEN, 'limit': limit } try: response = requests.get(endpoint, params=params) response.raise_for_status() media = response.json().get('data', []) logging.info(f"Fetched {len(media)} posts.") return media except requests.exceptions.HTTPError as http_err: logging.error(f"HTTP error occurred: {http_err}") except Exception as err: logging.error(f"Other error occurred: {err}") return [] -
Test Fetching Posts:
# test_instagram_fetcher.py from utils.instagram_fetcher import fetch_recent_posts if __name__ == "__main__": posts = fetch_recent_posts(limit=5) for post in posts: print(f"ID: {post['id']}") print(f"Caption: {post.get('caption', 'No Caption')}") print(f"Media Type: {post['media_type']}") print(f"Media URL: {post['media_url']}") print(f"Permalink: {post['permalink']}") print(f"Timestamp: {post['timestamp']}") print("-" * 40)- Run the Test:
python test_instagram_fetcher.py - Expected Output: A list of recent posts with their details.
- Run the Test:
Converting Images to Text Descriptions
To convert images into detailed text descriptions, you can utilize OpenAI’s GPT-4 with multimodal capabilities or other image captioning models like CLIP or BLIP.
Using OpenAI’s GPT-4 (Assuming Multimodal Support)
Note: As of my knowledge cutoff in September 2021, GPT-4’s multimodal capabilities were not available. Ensure you have access to the latest OpenAI models that support image inputs.
- Install OpenAI’s Latest SDK:
pip install --upgrade openai -
Utility Function for Image-to-Text Conversion:
# utils/image_to_text.py import openai import os import logging # Configure logging logging.basicConfig( filename='image_to_text.log', level=logging.INFO, format='%(asctime)s %(levelname)s:%(message)s' ) OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") openai.api_key = OPENAI_API_KEY def convert_image_to_text(image_url): try: # Download the image response = requests.get(image_url) response.raise_for_status() image_data = response.content # Convert image to text using OpenAI's API # Placeholder for actual multimodal API call # Replace with actual API endpoint and parameters response = openai.Image.create( file=image_data, purpose='image_captioning' ) caption = response.get('caption', 'No caption generated.') logging.info(f"Generated caption: {caption}") return caption except Exception as e: logging.error(f"Error converting image to text: {e}") return "Description not available."- Important: Replace the placeholder API call with the actual method provided by OpenAI for image captioning if available. As of now, you might need to use alternative models like BLIP or CLIP.
Using Alternative Models (e.g., BLIP)
If OpenAI’s GPT-4 does not support image inputs yet, consider using other models like BLIP (Bootstrapping Language-Image Pre-training) for image captioning.
- Install Required Libraries:
pip install transformers pip install torch -
Utility Function with BLIP:
# utils/image_to_text_blip.py from transformers import BlipProcessor, BlipForConditionalGeneration from PIL import Image import requests import logging # Configure logging logging.basicConfig( filename='image_to_text_blip.log', level=logging.INFO, format='%(asctime)s %(levelname)s:%(message)s' ) # Initialize BLIP processor and model processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base") model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base") def convert_image_to_text_blip(image_url): try: # Download the image response = requests.get(image_url) response.raise_for_status() image = Image.open(BytesIO(response.content)).convert('RGB') # Process the image and generate caption inputs = processor(image, return_tensors="pt") out = model.generate(**inputs) caption = processor.decode(out[0], skip_special_tokens=True) logging.info(f"Generated caption: {caption}") return caption except Exception as e: logging.error(f"Error converting image to text with BLIP: {e}") return "Description not available."- Usage:
# test_image_to_text_blip.py from utils.image_to_text_blip import convert_image_to_text_blip if __name__ == "__main__": image_url = "https://example.com/path-to-image.jpg" caption = convert_image_to_text_blip(image_url) print(f"Caption: {caption}") - Run the Test:
python test_image_to_text_blip.py - Expected Output: A generated caption describing the image.
- Usage:
Summarizing User Persona
Once you have text descriptions of the user’s posts, the next step is to summarize these into a coherent persona profile.
Implementation Steps:
-
Aggregate Descriptions: Collect all text descriptions generated from images and captions.
-
Summarize with OpenAI’s GPT-4:
# utils/summarize_persona.py import openai import os import logging # Configure logging logging.basicConfig( filename='summarize_persona.log', level=logging.INFO, format='%(asctime)s %(levelname)s:%(message)s' ) OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") openai.api_key = OPENAI_API_KEY def summarize_persona(descriptions): try: aggregated_text = "\n".join(descriptions) prompt = ( "Based on the following descriptions of a person's Instagram posts, create a comprehensive " "summary profile of the individual, highlighting their interests, personality traits, and " "lifestyle.\n\nDescriptions:\n" f"{aggregated_text}\n\nPersona Summary:" ) response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": prompt}], temperature=0.7, max_tokens=500 ) summary = response.choices[0].message.content.strip() logging.info("Persona summary generated successfully.") return summary except Exception as e: logging.error(f"Error summarizing persona: {e}") return "Persona summary not available." -
Usage Example:
# test_summarize_persona.py from utils.summarize_persona import summarize_persona if __name__ == "__main__": descriptions = [ "Post titled 'Sunset at the Beach': A beautiful sunset captured over the Pacific Ocean, highlighting vibrant oranges and purples.", "Comment: Loved your photo! The colors are stunning.", "Post titled 'Mountain Hike': Trekking through the Rocky Mountains, surrounded by snow-capped peaks and lush greenery." ] summary = summarize_persona(descriptions) print(f"Persona Summary:\n{summary}")- Run the Test:
python test_summarize_persona.py - Expected Output: A detailed summary profile of the user based on their Instagram activity.
- Run the Test:
Generating the Blog Post
With a summarized persona, you can now generate a blog post that encapsulates the user’s Instagram activity and persona.
Implementation Steps:
-
Utility Function to Generate Blog Post:
# utils/generate_blog_post.py import openai import os import logging # Configure logging logging.basicConfig( filename='generate_blog_post.log', level=logging.INFO, format='%(asctime)s %(levelname)s:%(message)s' ) OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") openai.api_key = OPENAI_API_KEY def generate_blog_post(persona_summary): try: prompt = ( "Write a detailed blog post about a person's recent Instagram activity based on the following " "persona summary.\n\nPersona Summary:\n" f"{persona_summary}\n\nBlog Post:" ) response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": prompt}], temperature=0.8, max_tokens=1500 ) blog_post = response.choices[0].message.content.strip() logging.info("Blog post generated successfully.") return blog_post except Exception as e: logging.error(f"Error generating blog post: {e}") return "Blog post not available." -
Usage Example:
# test_generate_blog_post.py from utils.summarize_persona import summarize_persona from utils.generate_blog_post import generate_blog_post if __name__ == "__main__": descriptions = [ "Post titled 'Sunset at the Beach': A beautiful sunset captured over the Pacific Ocean, highlighting vibrant oranges and purples.", "Comment: Loved your photo! The colors are stunning.", "Post titled 'Mountain Hike': Trekking through the Rocky Mountains, surrounded by snow-capped peaks and lush greenery." ] persona_summary = summarize_persona(descriptions) blog_post = generate_blog_post(persona_summary) print(f"Blog Post:\n{blog_post}")- Run the Test:
python test_generate_blog_post.py - Expected Output: A well-structured blog post summarizing the user’s Instagram activity and persona.
- Run the Test:
Orchestrating the Workflow
To bring all the components together, orchestrate the workflow in your main.py script.
main.py
# main.py
import os
from dotenv import load_dotenv
from utils.instagram_fetcher import fetch_recent_posts
from utils.image_to_text_blip import convert_image_to_text_blip
from utils.summarize_persona import summarize_persona
from utils.generate_blog_post import generate_blog_post
import logging
import schedule
import time
# Configure logging
logging.basicConfig(
filename='main.log',
level=logging.INFO,
format='%(asctime)s %(levelname)s:%(message)s'
)
def run_agent():
logging.info("Agent started.")
print("\n=== Instagram Persona Blog Generator ===\n")
# Fetch recent Instagram posts
posts = fetch_recent_posts(limit=10)
if not posts:
print("No recent Instagram activity found.")
logging.info("No recent Instagram activity found.")
return
# Convert images to text descriptions
descriptions = []
for post in posts:
media_type = post.get('media_type')
media_url = post.get('media_url')
caption = post.get('caption', '')
if media_type in ['IMAGE', 'CAROUSEL_ALBUM', 'VIDEO']:
description = convert_image_to_text_blip(media_url)
if caption:
description += f" Caption: {caption}"
descriptions.append(description)
print(f"Processed Post ID: {post['id']}")
else:
print(f"Unsupported media type for Post ID: {post['id']}")
logging.warning(f"Unsupported media type for Post ID: {post['id']}")
if not descriptions:
print("No descriptions generated from posts.")
logging.info("No descriptions generated from posts.")
return
# Summarize user persona
persona_summary = summarize_persona(descriptions)
print("\nPersona Summary Generated.\n")
logging.info("Persona summary generated.")
# Generate blog post
blog_post = generate_blog_post(persona_summary)
if blog_post:
# Save blog post locally
save_blog_post(blog_post)
else:
print("Failed to generate blog post.")
logging.error("Failed to generate blog post.")
logging.info("Agent completed.")
def save_blog_post(blog_content):
try:
os.makedirs('blog_posts', exist_ok=True)
timestamp = time.strftime("%Y%m%d-%H%M%S")
filename = f"blog_posts/blog_post_{timestamp}.md"
with open(filename, 'w', encoding='utf-8') as f:
f.write(blog_content)
print(f"Blog post saved successfully at {filename}")
logging.info(f"Blog post saved at {filename}")
except Exception as e:
print(f"Error saving blog post: {e}")
logging.error(f"Error saving blog post: {e}")
if __name__ == "__main__":
# Optionally, schedule the agent to run daily at a specific time
# For immediate run, call run_agent() directly
run_agent()
# Uncomment below to schedule
# schedule.every().day.at("09:00").do(run_agent)
# print("Scheduled the agent to run daily at 09:00 AM.")
# while True:
# schedule.run_pending()
# time.sleep(60) # wait one minute
Explanation
- Agent Execution:
- Fetching Posts: Retrieves recent Instagram posts.
- Image-to-Text Conversion: Converts each image to a text description using the BLIP model.
- Persona Summarization: Aggregates descriptions to create a persona summary.
- Blog Post Generation: Generates a blog post based on the persona summary.
- Saving the Blog Post: Saves the generated blog post as a Markdown file with a timestamp.
- Scheduling:
- The current setup runs the agent immediately upon execution.
- To automate the agent to run at a specific time daily, uncomment the scheduling section.
Handling Storage and Data Management
Efficient storage and management of data are crucial for scalability and maintainability.
Options:
- Local Storage:
- JSON Files: Store fetched posts and generated descriptions.
- SQLite Database: Manage data more efficiently with structured storage.
- Cloud Storage:
- AWS S3: Store images and blog posts.
- Google Cloud Storage: Alternative cloud storage solution.
Example: Using SQLite for Data Management
- Install SQLite Library:
pip install sqlite3 -
Utility Functions for Database Operations:
# utils/database.py import sqlite3 import logging # Configure logging logging.basicConfig( filename='database.log', level=logging.INFO, format='%(asctime)s %(levelname)s:%(message)s' ) def initialize_db(db_name='instagram_data.db'): conn = sqlite3.connect(db_name) cursor = conn.cursor() cursor.execute(''' CREATE TABLE IF NOT EXISTS posts ( id TEXT PRIMARY KEY, caption TEXT, media_type TEXT, media_url TEXT, permalink TEXT, timestamp TEXT, description TEXT ) ''') conn.commit() conn.close() logging.info("Database initialized.") def insert_post(post): try: conn = sqlite3.connect('instagram_data.db') cursor = conn.cursor() cursor.execute(''' INSERT OR IGNORE INTO posts (id, caption, media_type, media_url, permalink, timestamp, description) VALUES (?, ?, ?, ?, ?, ?, ?) ''', ( post['id'], post.get('caption', ''), post['media_type'], post['media_url'], post['permalink'], post['timestamp'], post.get('description', '') )) conn.commit() conn.close() logging.info(f"Inserted Post ID: {post['id']}") except Exception as e: logging.error(f"Error inserting post ID {post['id']}: {e}") def update_post_description(post_id, description): try: conn = sqlite3.connect('instagram_data.db') cursor = conn.cursor() cursor.execute(''' UPDATE posts SET description = ? WHERE id = ? ''', (description, post_id)) conn.commit() conn.close() logging.info(f"Updated description for Post ID: {post_id}") except Exception as e: logging.error(f"Error updating description for Post ID {post_id}: {e}") -
Integrate Database Operations in
main.py:# main.py (Additions) from utils.database import initialize_db, insert_post, update_post_description def run_agent(): initialize_db() # ... existing code ... # After fetching posts for post in posts: insert_post(post) media_type = post.get('media_type') media_url = post.get('media_url') caption = post.get('caption', '') if media_type in ['IMAGE', 'CAROUSEL_ALBUM', 'VIDEO']: description = convert_image_to_text_blip(media_url) if caption: description += f" Caption: {caption}" descriptions.append(description) update_post_description(post['id'], description) print(f"Processed Post ID: {post['id']}") else: print(f"Unsupported media type for Post ID: {post['id']}") logging.warning(f"Unsupported media type for Post ID: {post['id']}")
Scheduling and Automation
To ensure that the AI agent runs periodically (e.g., daily), implement scheduling using the schedule library.
Implementation Steps:
-
Modify
main.pyfor Scheduling:# main.py (Additions) import schedule def main(): # Initial run run_agent() # Schedule the agent to run daily at 09:00 AM schedule.every().day.at("09:00").do(run_agent) print("Scheduled the agent to run daily at 09:00 AM.") logging.info("Agent scheduled to run daily at 09:00 AM.") while True: schedule.run_pending() time.sleep(60) # Check every minute -
Run the Script in the Background:
- Option 1: Use a process manager like
pm2orsupervisordto keep the script running. - Option 2: Run the script in a screen or tmux session.
- Option 3: Deploy the script on a cloud server with appropriate uptime guarantees.
- Option 1: Use a process manager like
Error Handling and Logging
Robust error handling and comprehensive logging are essential for maintaining the health of your AI agent.
Best Practices:
-
Use Try-Except Blocks: Wrap API calls and critical operations in try-except blocks to catch and handle exceptions gracefully.
- Logging Levels:
- INFO: General operational messages.
- WARNING: Indications of potential issues.
- ERROR: Errors that prevent normal operation.
- CRITICAL: Severe errors causing termination.
- Centralized Logging:
- Use separate log files for different modules or combine them based on preference.
- Implement log rotation to prevent log files from growing indefinitely.
- Alerts and Notifications:
- Integrate with services like Slack, Email, or PagerDuty to receive real-time alerts on critical failures.
Deployment Considerations
Deploying your AI agent ensures it runs reliably without manual intervention.
Options:
- Cloud Servers:
- AWS EC2, Google Cloud Compute Engine, Azure Virtual Machines: Deploy your script on a virtual machine.
- Serverless Functions:
- AWS Lambda, Google Cloud Functions, Azure Functions: Suitable for event-driven executions.
- Note: May require adjustments for persistent tasks like scheduling.
- Containers:
- Docker: Containerize your application for portability.
- Kubernetes: Orchestrate multiple containers for scalability.
- CI/CD Pipelines:
- Integrate with GitHub Actions, GitLab CI/CD for automated deployments.
Deployment Steps:
-
Containerization with Docker:
- Create a
Dockerfile:# Dockerfile FROM python:3.9-slim WORKDIR /app COPY requirements.txt requirements.txt RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD ["python", "main.py"] - Create
requirements.txt:pip freeze > requirements.txt - Build and Run the Docker Container:
docker build -t instagram-persona-blog-generator . docker run -d --name blog_generator instagram-persona-blog-generator
- Create a
-
Using Process Managers:
- Install PM2:
npm install pm2 -g - Start the Script with PM2:
pm2 start main.py --interpreter=python3 pm2 save pm2 startup
- Install PM2:
-
Set Up Automatic Restarts:
- Ensure that your deployment method supports automatic restarts on failures or server reboots.
Ethical and Privacy Considerations
When handling user data, especially from social media platforms, it’s crucial to adhere to ethical standards and privacy laws.
Key Considerations:
- Consent:
- Ensure you have explicit permission to access and process the user’s Instagram data.
- Data Security:
- Store access tokens and sensitive information securely.
- Encrypt data at rest and in transit where applicable.
- Compliance with Instagram Policies:
- Adhere to Instagram’s Platform Policy to avoid violations that could lead to API access revocations.
- Data Minimization:
- Collect only the data necessary for the application’s functionality.
- Transparency:
- Inform users about how their data is being used, stored, and processed.
- Opt-Out Mechanisms:
- Provide users with options to revoke access or delete their data from your system.
Conclusion
Building a Multi-Model AI Agent that monitors Instagram posts, generates descriptive summaries, and crafts insightful blog posts is a multifaceted project that leverages the power of modern AI and API integrations. By following this guide, you’ve set up a robust pipeline that automates content analysis and generation, providing valuable insights into user behavior and facilitating effortless blog content creation.
Recap of Steps:
- Set Up Development Environment: Installed necessary tools and libraries.
- Obtain API Credentials: Secured access to Instagram’s Graph API and OpenAI’s services.
- Fetch Instagram Posts: Implemented functions to retrieve recent posts.
- Convert Images to Text: Utilized multimodal models like BLIP for image captioning.
- Summarize Persona: Aggregated descriptions to create a user persona profile.
- Generate Blog Post: Leveraged GPT-4 to craft a comprehensive blog post.
- Orchestrate Workflow: Combined all components into a seamless pipeline.
- Handle Storage and Data: Managed data using SQLite for structured storage.
- Implement Scheduling: Automated the agent’s execution using the
schedulelibrary. - Ensure Robustness: Added error handling and logging for maintenance and debugging.
- Deploy the Agent: Considered deployment options for reliable operation.
- Adhere to Ethics and Privacy: Emphasized responsible data handling practices.
Future Enhancements:
- Advanced NLP Techniques: Incorporate sentiment analysis or trend detection for deeper insights.
- User Interface: Develop a web or desktop application interface for easier interaction.
- Integration with Other Platforms: Extend functionality to monitor and analyze posts from other social media platforms.
- Enhanced AI Models: Utilize more sophisticated AI models as they become available to improve description accuracy and summary quality.
Embarking on this project not only enhances your technical prowess but also opens doors to innovative content management and creation strategies. Happy Coding!
Additional Resources:
- Instagram Graph API Documentation
- OpenAI API Documentation
- BLIP Image Captioning Model
- Python-dotenv Documentation
- Schedule Library Documentation
- SQLite Documentation
Feel free to reach out if you encounter any challenges or have further questions as you develop your AI agent!
Featured Posts
Related Posts
Building an AI-Powered Filename Generator Chrome Extension
February 25, 2025# Building an AI-Powered Filename Generator Chrome Extension ## Introduction Managing files efficiently can be a ch...
Read MorePrivacy Policy
February 23, 2025# Privacy Policy for AI Filename Generator ## 1. Introduction The **AI Filename Generator** Chrome Extension respect...
Read MoreRedDiss
February 14, 2025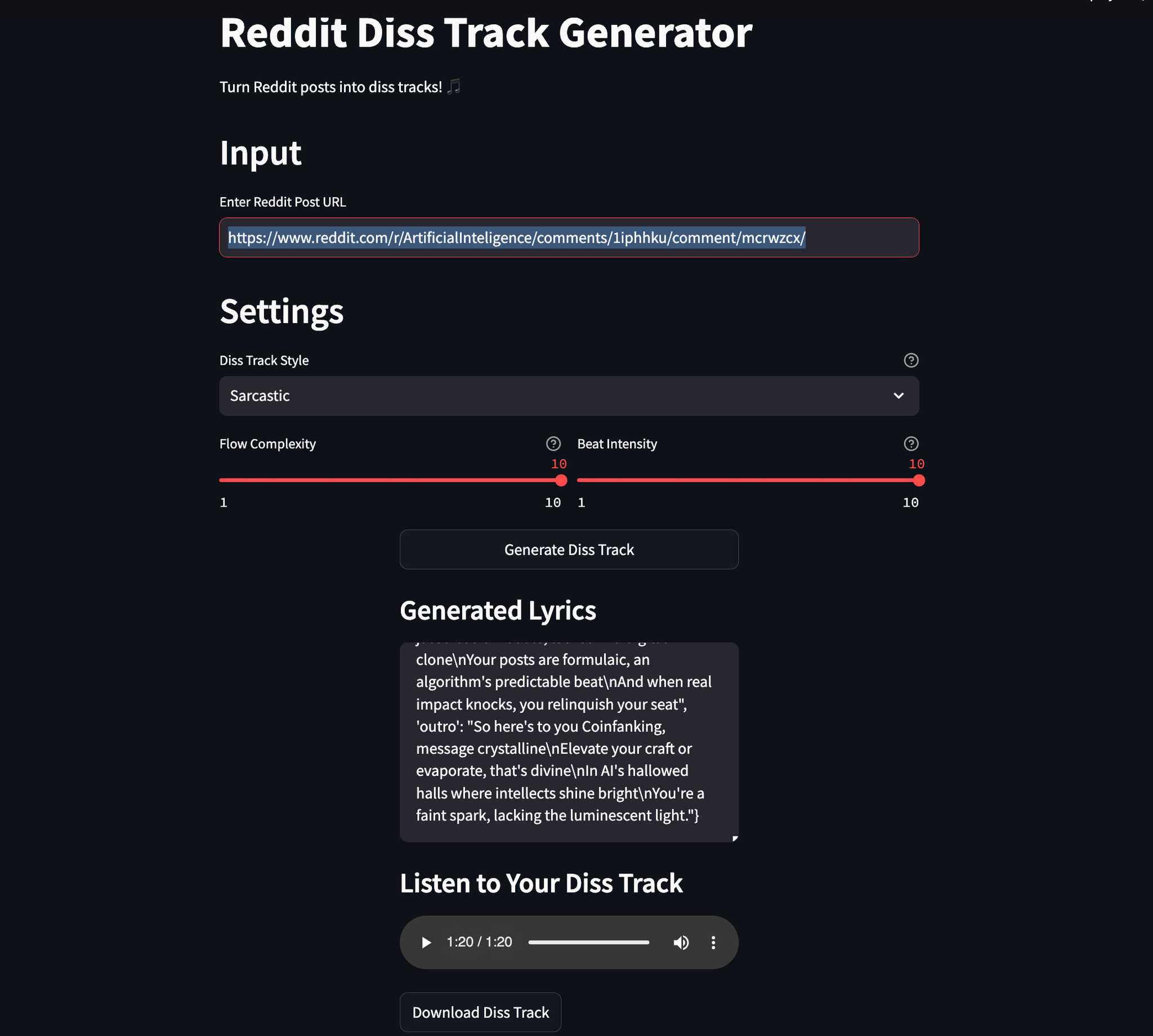 [Repo](https://github.com/kliewerdaniel/RedDiss.git) # Behind the Scenes of RedD...
Read MoreOllama Smolagents Open Deep Research Integration
February 05, 2025**Unlocking Open-Source AI Power: How to Run Your Own Deep Research Agent with Ollama and Smolagents** The AI land...
Read More